Block AI Crawlers
by lastsplash (a11n) on WordPress.org
Tell AI (Artificial Intelligence) companies not to scrape your site for their AI products.
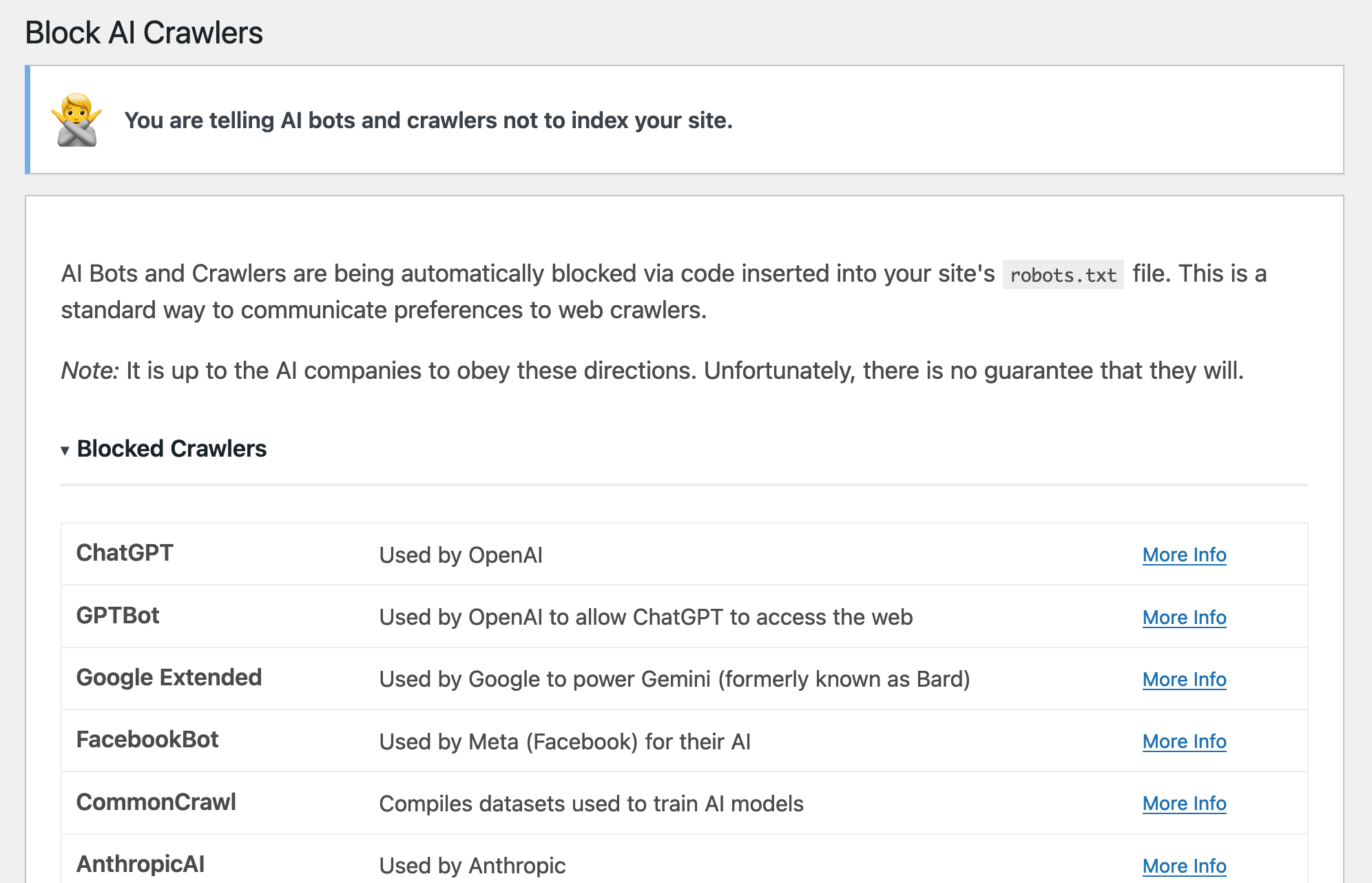
Plugin page showing which crawlers are blocked
Protect Your Content from AI Scraping
This plugin helps you prevent AI crawlers from using your content as training data for their products. By updating your site’s robots.txt, it blocks common AI crawlers and scrapers, aiming to protect your content from being used in the training of Large Language Models (LLMs).
Features
Blocks AI Crawlers
Includes:
- OpenAI – Blocks crawlers used for ChatGPT
- Google – Blocks crawlers used by Google’s Gemini AI products
- Facebook / Meta – Used for Facebook’s AI training
- Anthropic AI – Blocks crawlers used by Anthropic
- Perplexity – Block crawlers used by Perplexity
- Applebot – Blocks crawlers used by Apple
- … and more!
Experimental Meta Tags
The plugin adds the “noai, noimageai” directive to your site’s meta tags, instructing AI bots not to use your content in their datasets. Please note that these tags are experimental and have not been standardized.
Custom robots.txt Rules
Have custom entries for your robots.txt file? You can now add them directly through the plugin!
Usage
After activation, the plugin will automatically update your robots.txt and add the necessary meta tags. No further configuration is required, but you can check the settings page for a full list of blocked crawlers.
Limitations
While this plugin aims to block specified crawlers, it cannot guarantee complete protection against all forms of scraping, as some bots may disregard robots.txt directives.
Support
For questions or support, please post on the forums or on GitHub.